Project Overview
Querying databases using natural language has become increasingly accessible thanks to advancements in AI-powered SQL generation. However, the accuracy of these systems often depends on how well the model understands the structure and semantics of the database schema. In this project, we evaluate the performance of Peaka AI Agent, a no-code tool that converts natural language questions into executable SQL queries, by using the Spider dataset as the testbed.TL;DR
If you’d like to skip the implementation details, you can review the finished code on Peaka’s GitHub account. Follow the instructions in the README to run the project locally. You can also try the live demo.What is Peaka?
Peaka is a no-code data management platform that connects and transforms data from multiple sources, making it easier to access, manage, and utilize across various applications. Peaka provides a unique semantics generation tool that completes table columns with human-readable descriptions. These semantics help the AI Agent better understand schema context, leading to more accurate SQL generation. We’ll be showing you how applying Peaka’s semantics tool can narrow the gap between AI-generated queries and ground-truth Spider SQL results, especially when raw schema names are vague or ambiguous.What is Spider?
Spider is a large-scale, cross-domain text-to-SQL benchmark designed to evaluate the performance of natural language interfaces for complex database queries. Unlike simpler datasets, Spider challenges systems to understand diverse schemas and generate accurate SQL queries from natural language questions without access to query templates or hard-coded logic. It contains 10,000 natural language questions across 200 databases covering a wide range of real-world scenarios. Each question is paired with a ground truth SQL query and is designed to test a model’s ability to generalize. Spider is used to assess the effectiveness of semantic parsers and AI agents that attempt to bridge the gap between users and relational databases using plain languages.What is Snowflake?
Snowflake is a modern cloud-based data warehouse platform known for its scalability, speed, and SQL-native environment. In the context of Spider benchmark, Snowflake serves as the execution environment for evaluating generated SQL queries. Since Spider provides natural language questions and corresponding SQL queries, these can be executed against databases hosted in Snowflake to validate whether the SQL returns correct results.What is a Semantic Layer?
A semantic layer is a method for making data easier to understand and utilize. It connects technical database terms to more familiar business language. By defining key terms, establishing relationships between tables, and implementing standard filters, a semantic layer helps tools like AI agents generate more accurate and meaningful queries.Schema Clarity and RAG
- Use clear schema definitions: The schema should be well-documented by listing all tables, columns, data types, and their relationships to each other.
- Add context to column names: When column names are unclear (like cust_id), include descriptions such as “customer identifier” so the model can have a better understanding of meaning.
- Use RAG for real-time schema access: Retrieval-Augmented Generation allows your system to pull in up-to-date schema information when generating queries, thereby reducing errors caused by outdated or missing context.
- Leverage query templates: Keep a library of tried and true query patterns. Instead of generating queries from scratch, the model can modify these blueprints to fit new questions more accurately.
Prerequisites
Before running this project, make sure you have the following:- Python 3.8+ installed
- Spider Text-to-SQL Dataset for generating natural language questions. You can find it here.
- Peaka Studio account with API key and project setup. You can follow the steps in the Peaka documentation to generate a key.
- Snowflake account or access(for Spider execution in Snowflake syntax)
- The following Python packages installed:
Tech Stack
| Tool/Library | Purpose |
|---|---|
| Peaka | A zero-ETL data integration platform with single step context generation capability |
| Spider Dataset | Source of natural language questions and structured DB schemas |
| Snowflake SQL | Backend execution engine used by Spider for SQL result generation |
| Requests | Used to make authenticated API calls to Peaka AI Agent |
| Streamlit | To build an interactive web UI for comparing question results |
Let’s Start
Combining Natural Language Questions with SQL Queries
In this step, we prepare a dataset that combines:- Natural languages questions
- Their corresponding Snowflake SQL queries
- The associated database context
- The result file name
Step 1: Load Natural Language Questions
Import the required libraries:- instance_id: used to match with SQL file
- instruction: the NL question
- db_id: the name of database
Step 2: Matching SQL Files to Questions
Each SQL file in sql/ is named using instance_id (e.g. q_1001.sql). We read the file and try to transpile it to Trino dialect that Peaka recognize using sqlglot. First import the necessary libraries for SQL transpilation from sqlglot:TO_NUMBER→CAST AS DECIMALREGEXP_EXTRACT→ compatible Trino equivalent
Step 3: Assemble the Output Dataset
Combine everything — instruction, database, transpiled SQL, and the result file name — into a structured list.Sending Instructions to Peaka AI Agent
Peaka serves a powerful data management backend, enabling seamless integration between your front-end apps and structured data sources. It provides a unified layer to manage, query, and expose data securely. With features like API generation, data federation, and access controls, Peaka is designed to support use cases such as AI agents, dashboards, and automation tools. You can visit our documentation section to learn more about how Peaka handles data management. Prerequisites For this step, you must create Peaka project and have its ID and an API key. The Peaka project must contain one or more databases already integrated from snowflake and ready to be queried. Now, use the outputs.json file from the previous step, and for each instruction:- Send a GET request to retrieve schema info.
- Send a POST request to the Peaka AI agent with user question and schema
- Collect the AI’s SQL response.
- Measure response time.
- Save all results in a structured file.
Step 1: Loading Needed Dependencies
Start by importing requests, time, json, and os for API calls and file handling.GET_URL: Fetches info about your Peaka project (including projectId).
POST_URL: Sends questions to the AI agent in that project.Headers include your token for authorization:
Step 2: Get Peaka Project ID
Step 3: Loop through Instructions and Send to the AI Agent
Step 4: Process Response and Collect Results
Visualizing Results with Streamlit
To explore and compare the AI-generated SQL outputs visually, I built a simple Streamlit Dashboard. It lets you browse through databases and its instructions, view Peaka’s results alongside the original Spider queries, and evaluate differences if any. You can find the full Streamlit implementation in the Github repository. To launch the app locally, just run: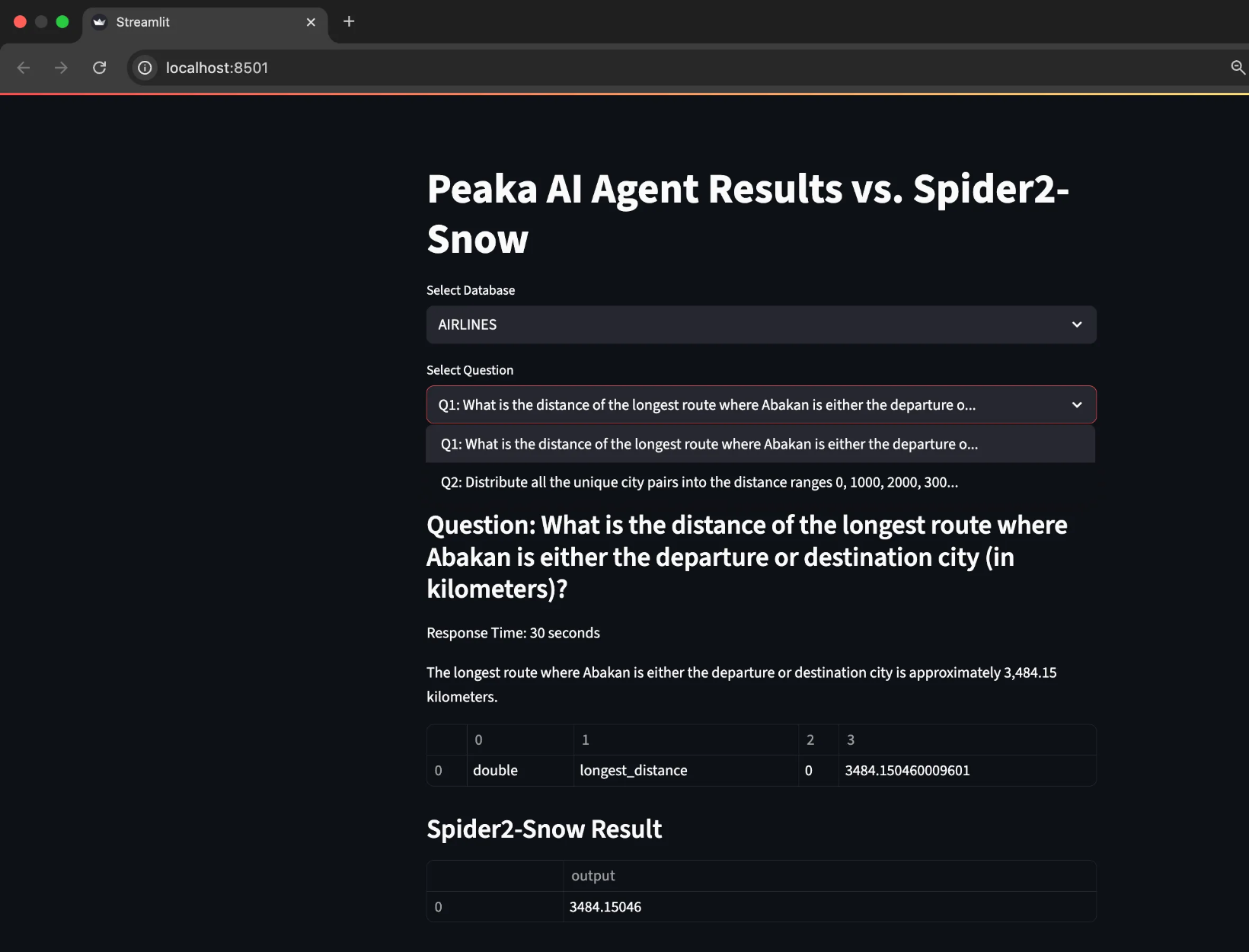
Enhancing Accuracy with Peaka’s Semantic Tool
Peaka comes with a tool that analyzes the database schema and automatically generates rich semantic metadata (such as column descriptions, table purposes, and relationships), which are then used by the AI agent during query generation. By providing deeper context about the data, the agent is able to produce significantly more accurate SQL outputs, enhancing the performance of the agent. I will walk you through how you can simply generate semantics of the tables you are working on. As an example, we’ll generate semantics for a Snowflake Table named “aircrafts_data” that contains information about different aircrafts items, including their code, model, and ranges.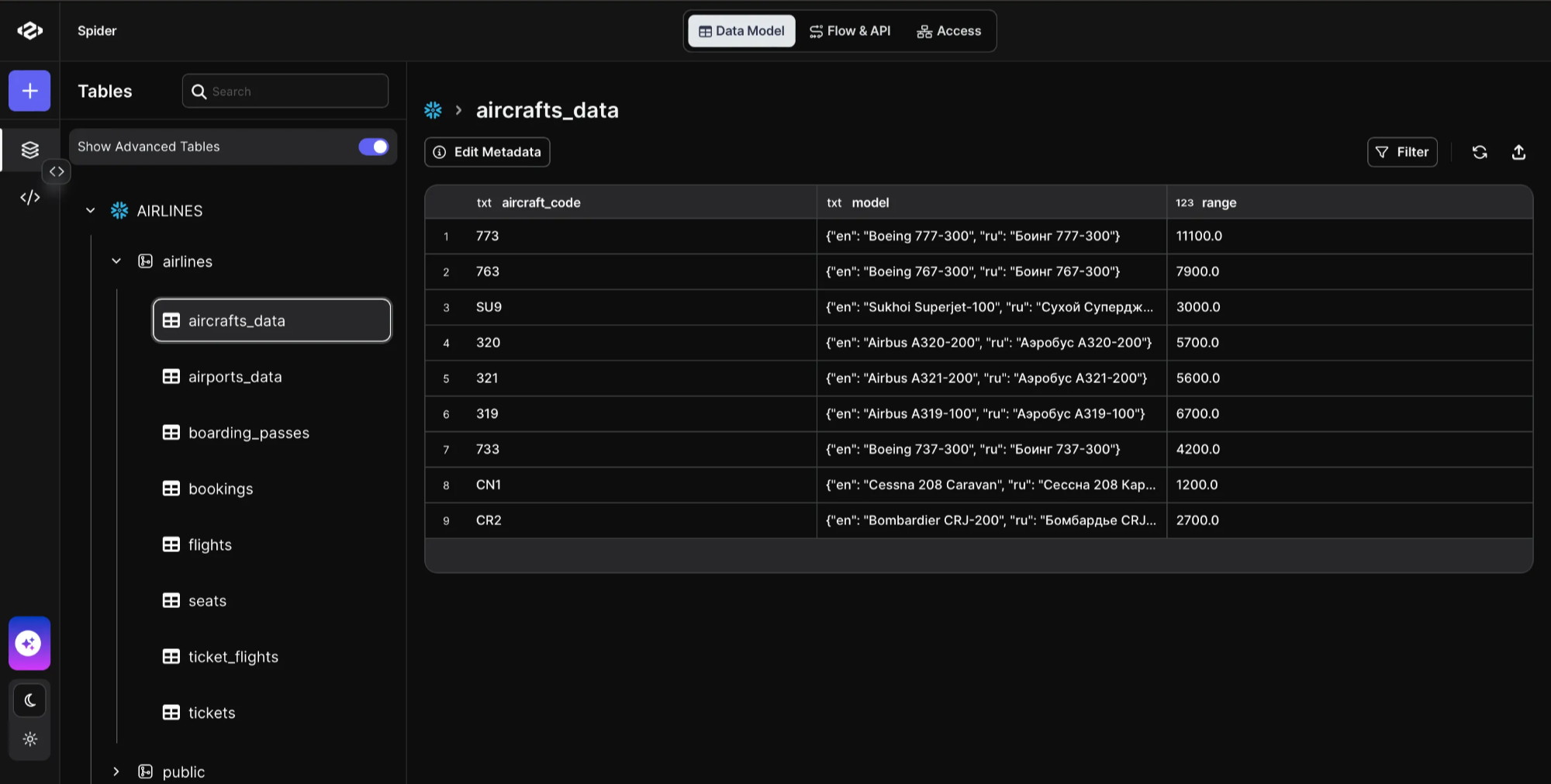 Follow these steps along:
Follow these steps along:
- Open the Edit Metadata Modal: Click the “Edit Metadata” button above the table. This action opens a modal where you can define more detailed description of the table and columns.
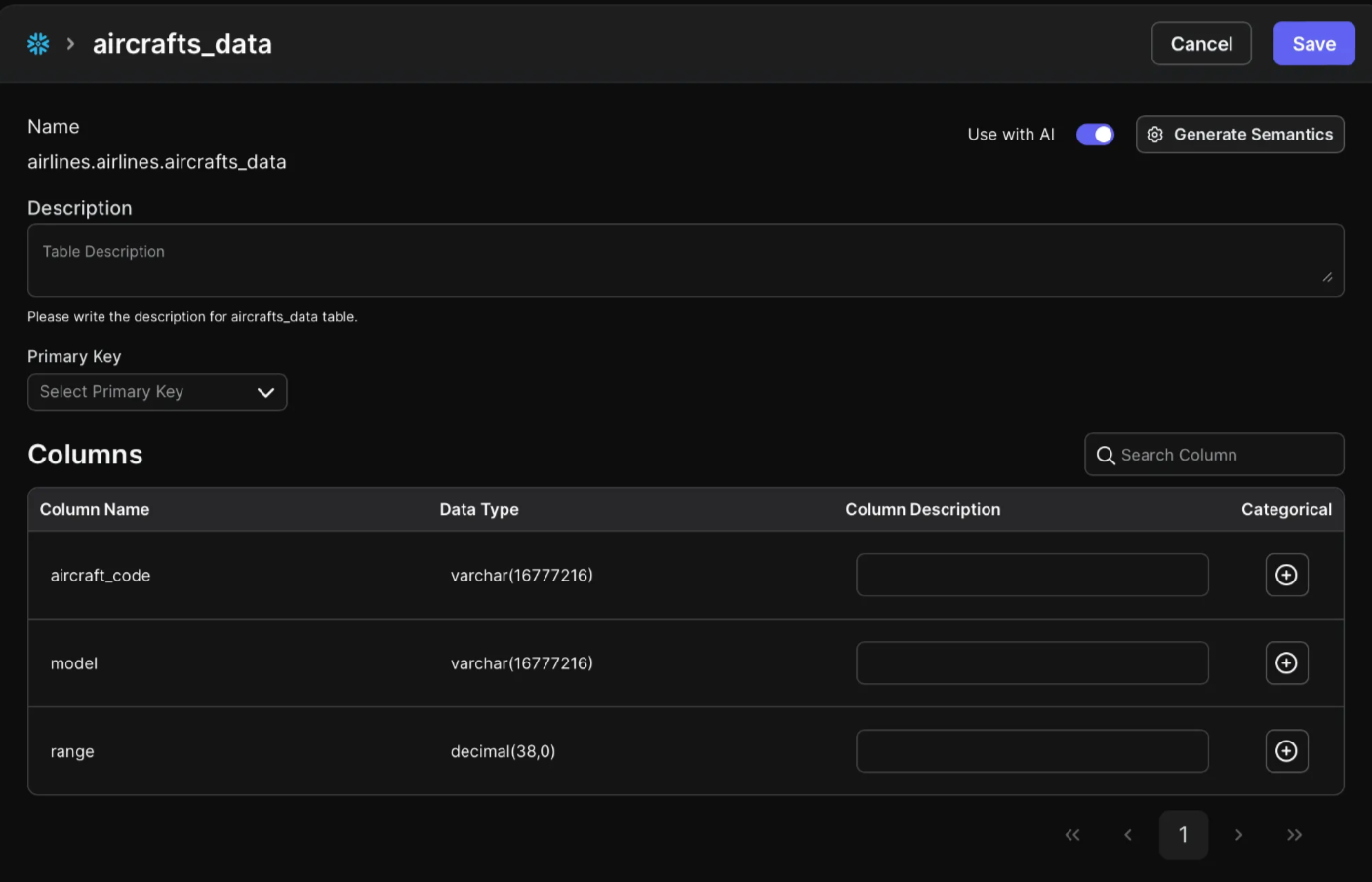 As you can see the descriptions are initially empty before generating semantics.
As you can see the descriptions are initially empty before generating semantics.
- Open Generating Semantics Modal: To add more context to the table click the “Generate Semantics” button on the right side above the table.
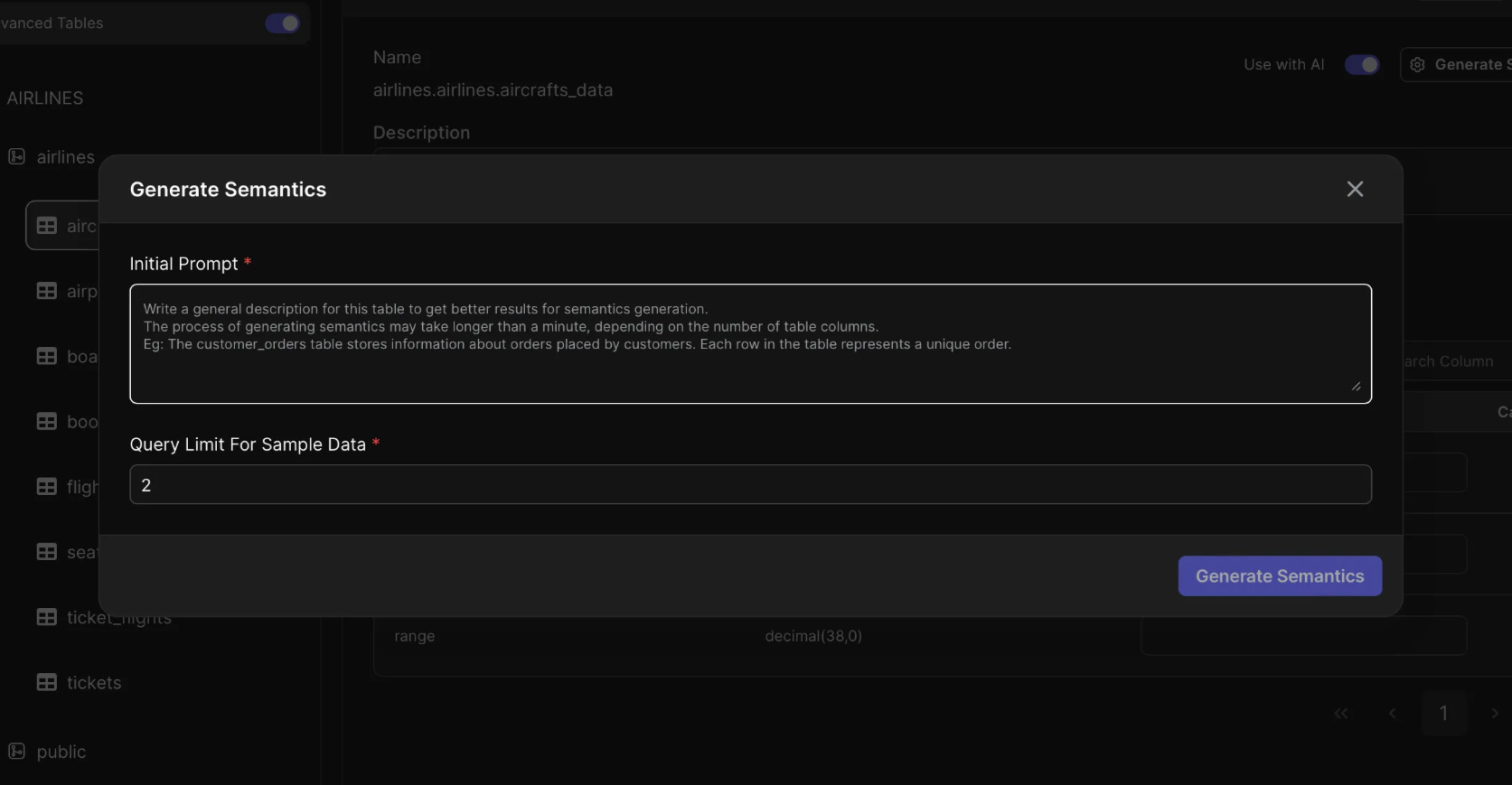 To ensure accurate semantic generation, an initial prompt is included upfront to frame how the assistant should interpret incoming queries. For this example, you can add something like “code, models and ranges of aircrafts”.
To ensure accurate semantic generation, an initial prompt is included upfront to frame how the assistant should interpret incoming queries. For this example, you can add something like “code, models and ranges of aircrafts”.
- Generate Semantics: after adding initial prompt, click “Generate Semantics” and wait until you see the previous table description columns has been filled with explanations about the data.
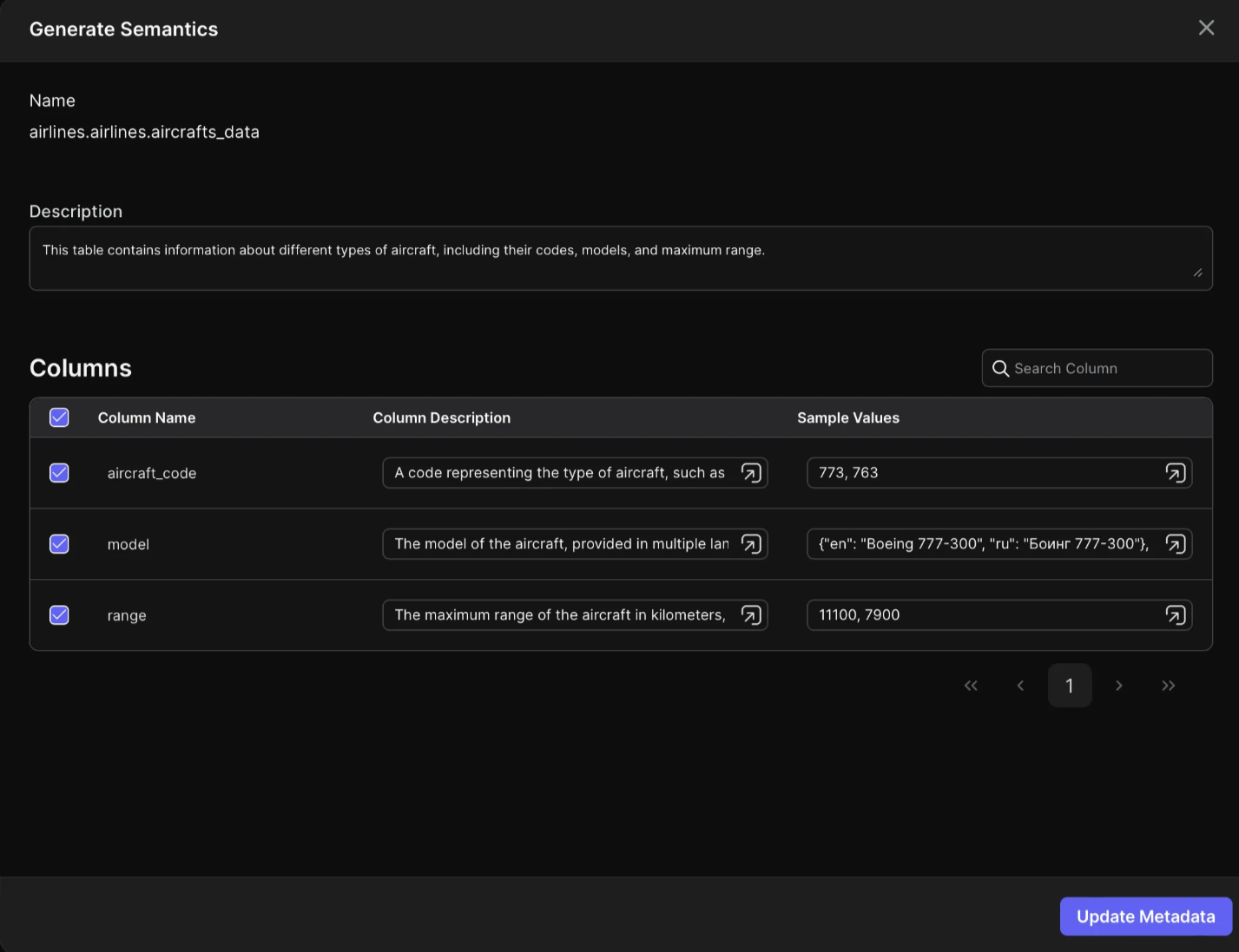 Columns descriptions and sample values has been added automatically by Peaka.
Columns descriptions and sample values has been added automatically by Peaka.
- Update Metadata: to save the data semantics click “Update Metadata” button.
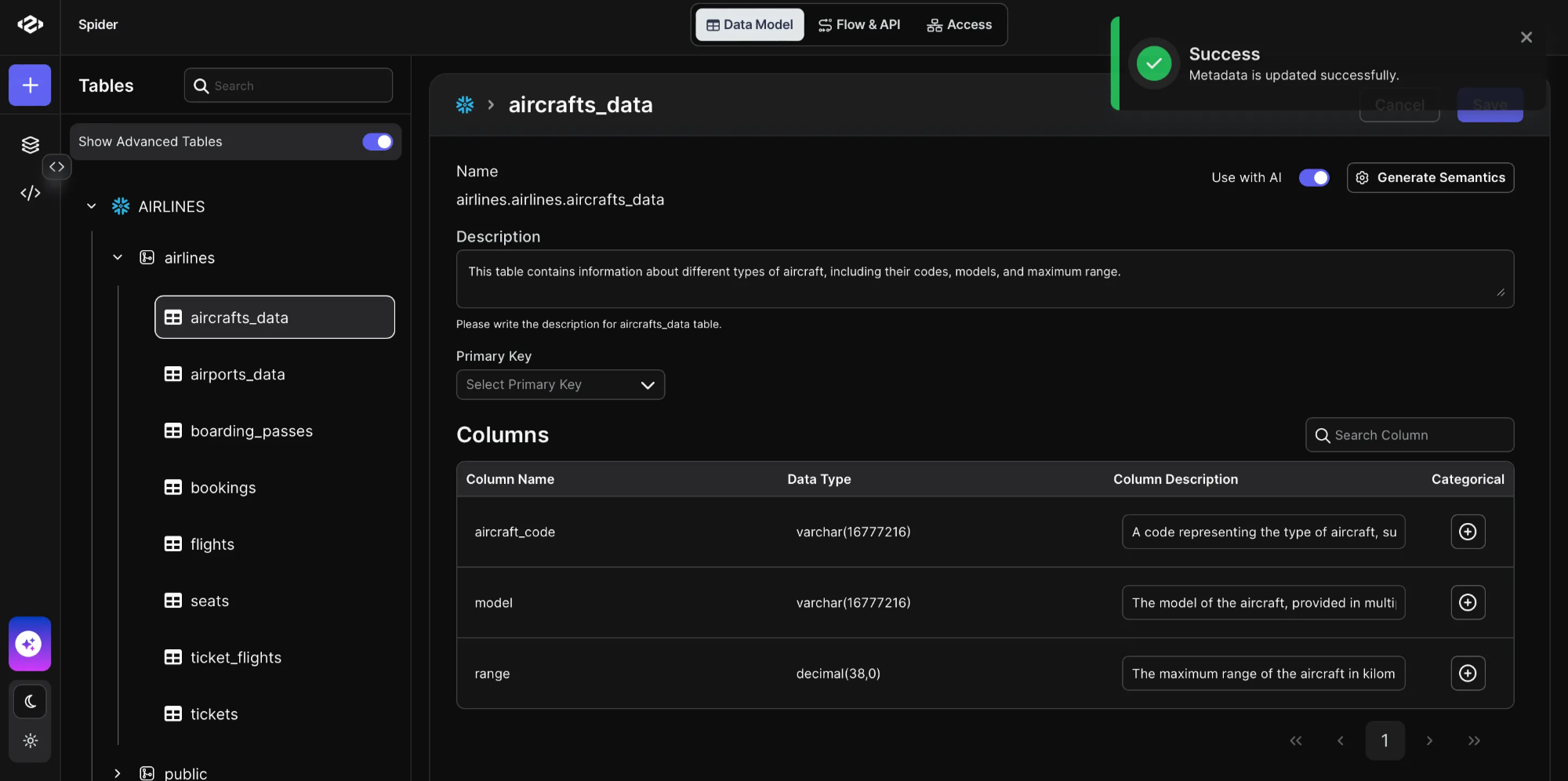 That’s it! Now the metadata of our table has been updated successfully and will be used effectively by the AI agent while retrieving the data and generating more accurate SQL queries.
Let’s look at a specific example that demonstrates the difference before and after applying Peaka’s semantic tool. The same NL instruction is processed by the AI agent in both cases. The resulting answer shows how semantics lead to more accurate interpretation and alignment with the expected logic from the Spider benchmark.
That’s it! Now the metadata of our table has been updated successfully and will be used effectively by the AI agent while retrieving the data and generating more accurate SQL queries.
Let’s look at a specific example that demonstrates the difference before and after applying Peaka’s semantic tool. The same NL instruction is processed by the AI agent in both cases. The resulting answer shows how semantics lead to more accurate interpretation and alignment with the expected logic from the Spider benchmark.
 Peaka’s initial results significantly lag behind Spider’s performance before table semantics are generated for the query.
Peaka’s initial results significantly lag behind Spider’s performance before table semantics are generated for the query.
 After generating the Semantics of data, we retrieve an accurate answer more quickly.
After generating the Semantics of data, we retrieve an accurate answer more quickly.
Key Takeaways
- Spider is a widely used benchmark for evaluating the performance of natural language to SQL systems, offering complex, multi-domain instructions and queries.
- Transpiring SQL syntax makes Snowflake compatible with Spider queries.
- Peaka AI Agent was tested using real Spider instructions, with responses retrieved via API.
- Response accuracy improves significantly when adding semantic to the data with the help of Peaka, as it adds meaning and structure to database columns.